Qianfan-OCR惊艳效果:多语言混排技术文档(中英日)同步识别与分段输出
同步识别与分段输出)
更多精彩文章

喂了虾粮的龙虾,该给你赚钱了
money-never-sleep技能详情见 OpenClaw 官方技能市场 OpenClaw / Hermes 技能:https://clawhub.ai/sopaco/money-never-sleep GitHub 源码:https://github.com/sopaco/money-never-sleep一、那个晚上,我又一次失眠了 凌晨三点,窗外…...

C语言常见概念以及数据类型和变量
C语言常见概念以及数据类型和变量一.ASCⅡ码查表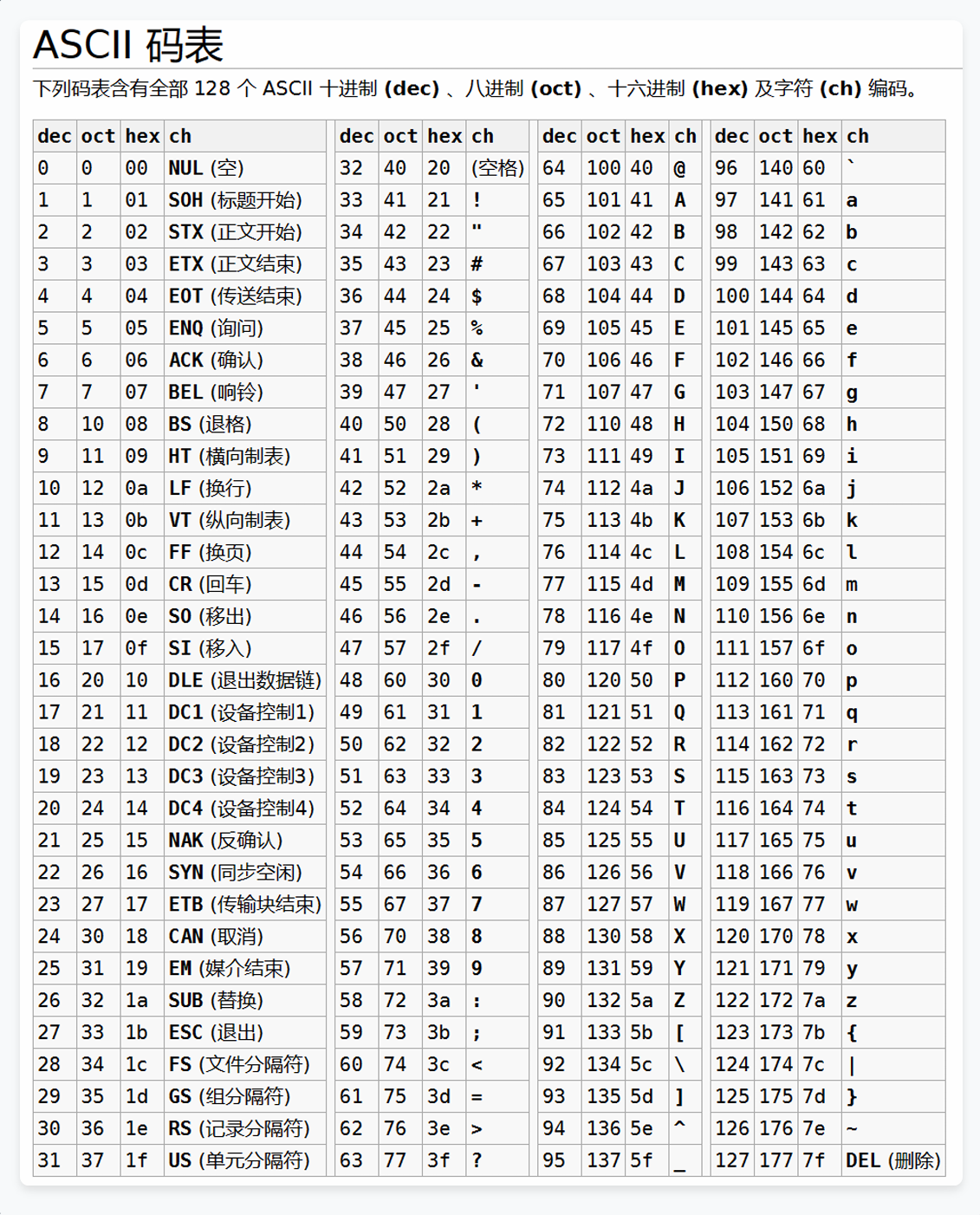1.常见常用的ASCⅡ码,速记二.转义字符2.1.常见转义字符2.2特殊转义字符三.编程里的五种语句类型四.注释及其注意事项五.数据类型和变量5…...

哔哩下载姬DownKyi:5分钟掌握B站视频下载的终极免费方案
哔哩下载姬DownKyi:5分钟掌握B站视频下载的终极免费方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

前端三剑客 vs Vue.js:核心区别解析
好的,这是一个关于前端技术的常见问题。我们来理清 HTML CSS JavaScript(通常称为“前端三剑客”)与 Vue.js(一个流行的 JavaScript 框架)之间的区别:核心概念不同HTML CSS JavaScript: 这是…...

【SAP Basis】从SU01出发:深入解析SAP用户账号管理的核心配置与实战
1. SU01入门:SAP用户管理的核心入口 第一次接触SAP Basis管理时,我被满屏的事务码搞得晕头转向。直到导师指着SU01说:"这是你未来每天都要打交道的老朋友",我才意识到用户管理的重要性。SU01就像SAP系统的门禁控制台&am…...
)
AI代码配额管理实战指南:7大行业真实配额模型+3类超限预警SOP(附2026大会未发布白皮书节选)
第一章:AI代码配额管理的范式跃迁与大会使命 2026奇点智能技术大会(https://ml-summit.org) 传统资源配额模型正面临根本性挑战:当大语言模型驱动的代码生成器每秒产出数百行可执行逻辑,静态CPU/内存阈值已无法表征真实开发意图与语义负载。…...

7-Zip终极指南:免费开源的文件压缩神器如何改变你的文件管理方式
7-Zip终极指南:免费开源的文件压缩神器如何改变你的文件管理方式 【免费下载链接】7z 7-Zip Official Chinese Simplified Repository (Homepage and 7z Extra package) 项目地址: https://gitcode.com/gh_mirrors/7z1/7z 你是否曾为电脑空间不足而烦恼&…...